SemEval 2021 Task 5: Toxic Spans Detection
Moderation is crucial to promoting healthy online discussions. Although several toxicity (abusive language) detection datasets and models have been released, most of them classify whole comments or documents, and do not identify the spans that make a text toxic. But highlighting such toxic spans can assist human moderators (e.g., news portals moderators) who often deal with lengthy comments, and who prefer attribution instead of just a system-generated unexplained toxicity score per post. The evaluation of systems that could accurately locate toxic spans within a text is thus a crucial step towards successful semi-automated moderation.
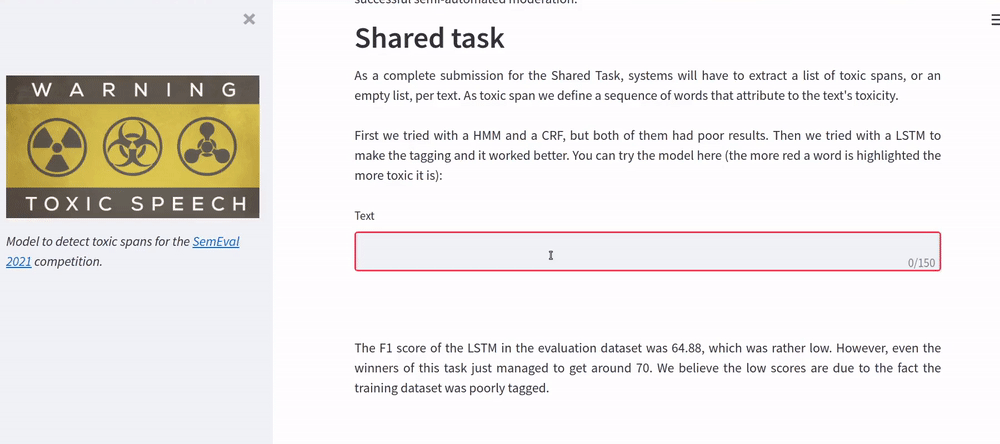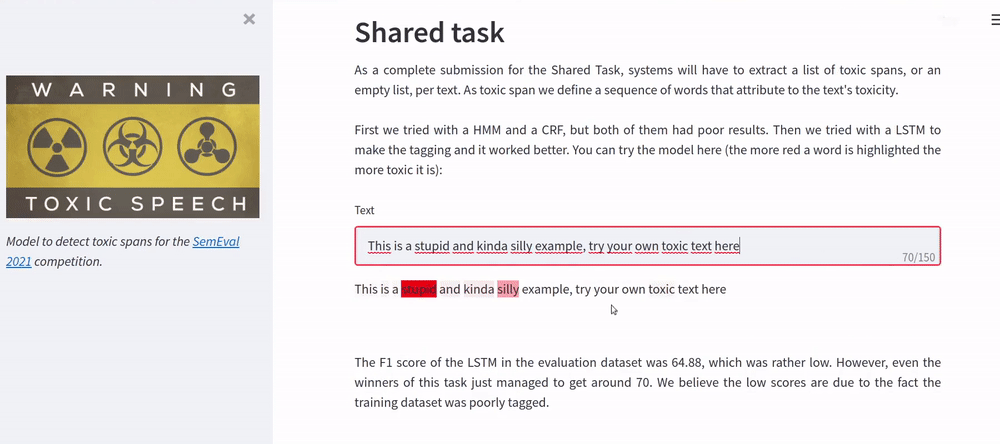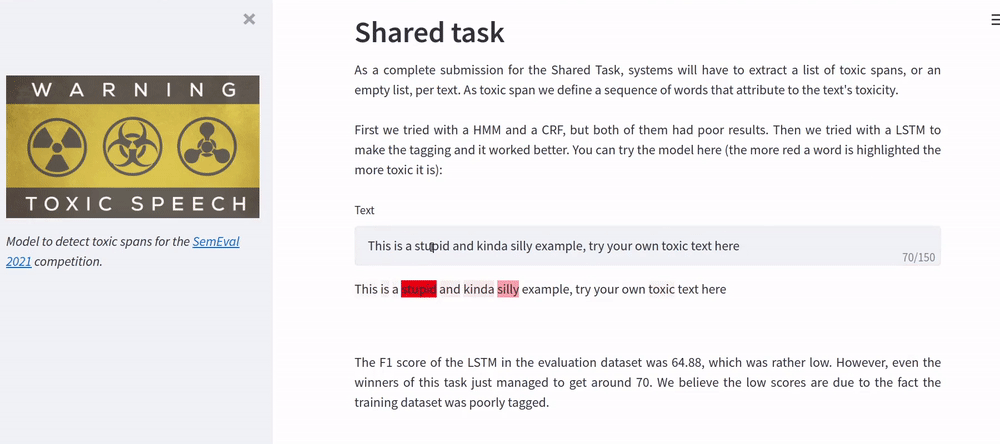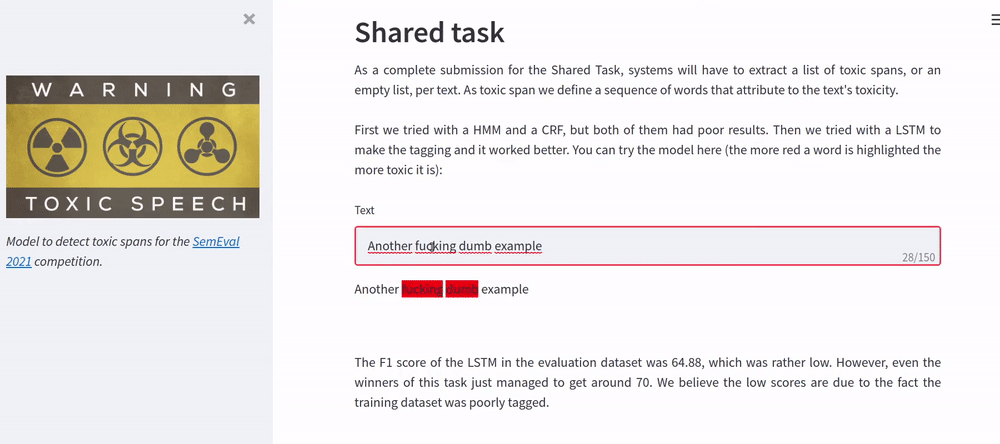
We trained a LSTM to perform the tagging of the toxic spans. The F1 score of the LSTM in the evaluation dataset was 64.88, which was rather low. However, even the winners of this task just managed to get around 70, we believe the low scores are due to the fact the training dataset was poorly tagged. The page of the competition is here.
The code with more explanations is in my GitHub SemEval2021.